It is essential to be aware of the financial risk associated with the invested product. In my last blog, I explained that one has to perform costly numerical simulations to understand the risks associated with a financial product.
The financial instruments are valuated via the dynamics of short-rate models, based on the convection-diffusion-reaction partial differential equations (PDEs). The choice of the short-rate model depends on the underlying financial instrument. Some of the prominent financial models are the one-factor Hull-White model, the shifted Black Karasinski model, and the two-factor Hull-White model. These models are calibrated based on several thousand simulated yield curves that generate a high dimensional parameter space. In short, to perform the risk analysis, the financial model is needed to be solved for such a high dimensional parameter space, which requires efficient algorithms. My Ph. D. aims to develop an approach that will perform such a computationally costly task as fast as possible but with a reliable outcome. Thus, I am developing a model order reduction approach.
Now, let us dive into the main topic. The model hierarchy simplifies the process of obtaining a reduced-order model (ROM) and is shown in the Fig. 1.
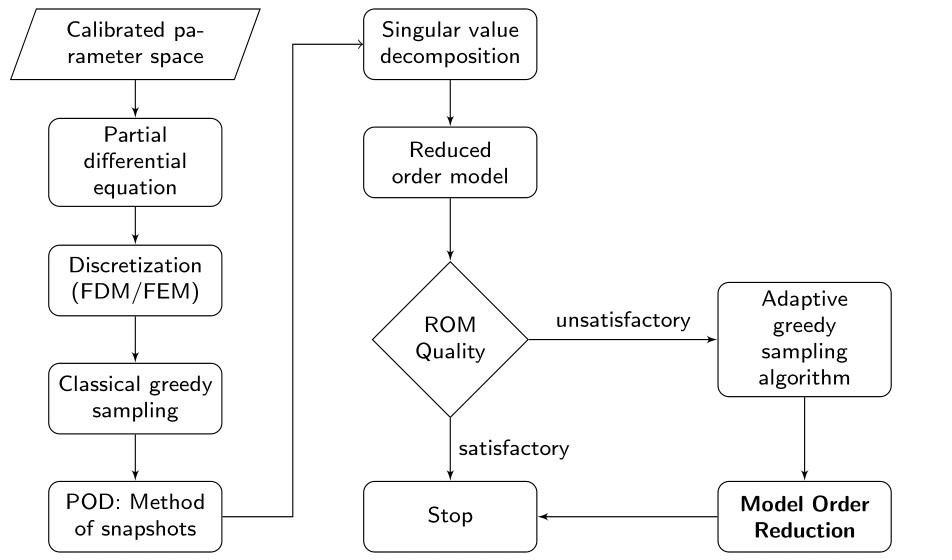
It starts by discretizing the partial differential equation using either the finite difference method (FDM) or the finite element method (FEM). The discretized model is known as the full order model (FOM). To obtain a reduced-order model, one has to compute a reduced-order basis (ROB). To do so, the proper orthogonal decomposition (POD) approach relies on the method of snapshots. The snapshots are obtained by solving the FOM for some training parameters, which are further combined into a single matrix know as the snapshot matrix. Subsequently, the ROB is obtained by computing the truncated singular value decomposition (SVD) of the snapshot matrix. Finally, the FOM is projected onto the ROB to get the reduced-order model. One can easily infer that the quality of the ROB is based on the selection of training parameters. In this work, the training parameters are chosen based on either the greedy sampling or the adaptive greedy sampling approaches.
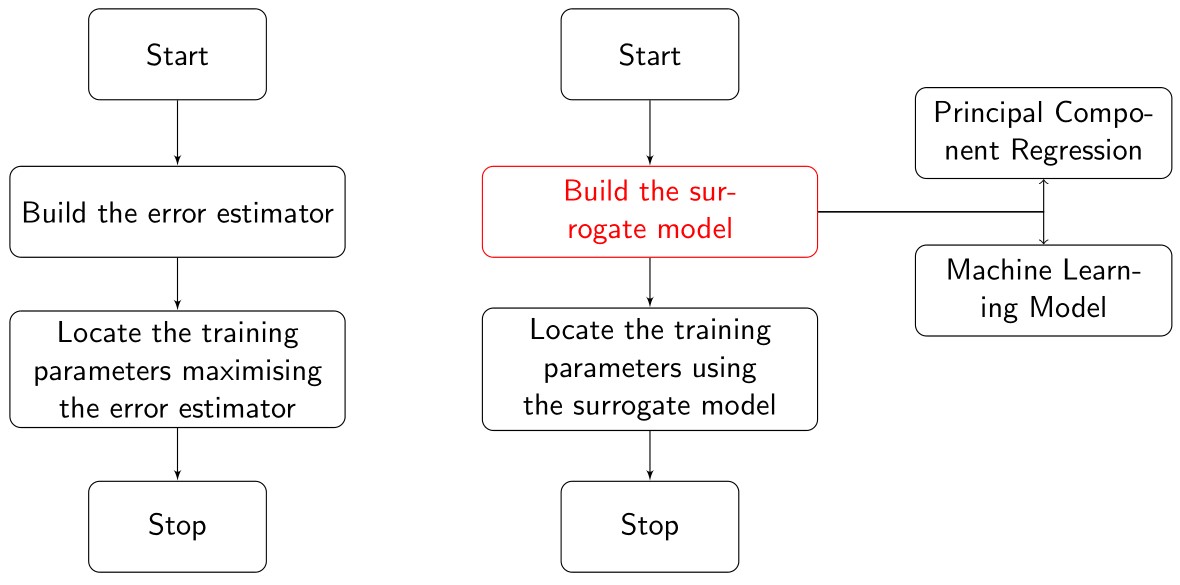
The greedy sampling technique selects the parameters at which the error between the ROM and the FOM is maximum. Further, the ROB is obtained using these selected parameters. The calculation of the relative error is expensive, so instead, the residual error associated with the ROM is used as an error estimator. However, it is not reasonable to compute an error estimator for the entire parameter space. This problem forces us to select a pre-defined parameter set as a subset of the high dimensional parameter space to train the greedy sampling algorithm. We usually select this pre-defined subset randomly. But, a random selection may neglect the crucial parameters within the parameter space. Thus, to surmount this problem, I implemented an adaptive greedy sampling approach. The algorithm chooses the most suitable parameters adaptively using an optimized search based surrogate modeling. This approach evades the cost of computing the error estimator for each parameter within the parameter space and instead uses a surrogate model to locate the training parameter set. I have built the surrogate model using two approaches: (i) the principal component regression model (ii) machine learning model. See our pre-print available on Arxiv for more details [1].
References:
[1] A. Binder, O. Jadhav, and V. Mehrmann. Model order reduction for parametric high dimensional models in the analysis of financial risk. Technical report, 2020. https://arXiv:2002.11976.
About the author
Onkar Sandip Jadhav is an early-stage researcher (ESR6) in the ROMSOC project. He is a PhD student at the Technische Universität Berlin (Germany) and is working in collaboration with MathConsult GmbH (Austria). In his research he is working on a parametric model order reduction (MOR) approach aiming to develop a new MOR methodology for high-dimensional convection-diffusion reaction PDEs arising in computational finance with the goal to reduce the computational complexity in the analysis of financial instruments.
